分布式唯一ID-数据库生成

是不是一定要基于外界的条件才能满足分布式唯一ID的需求呢,我们能不能在我们分布式数据库的基础上获取我们需要的ID?
由于分布式数据库的起始自增值一样所以才会有冲突的情况发生,那么我们将分布式系统中数据库的同一个业务表的自增ID设计成不一样的起始值,然后设置固定的步长,步长的值即为分库的数量或分表的数量。
以MySQL举例,利用给字段设置auto_increment_increment和auto_increment_offset来保证ID自增。
auto_increment_offset:表示自增长字段从那个数开始,他的取值范围是1 … 65535。auto_increment_increment:表示自增长字段每次递增的量,其默认值是1,取值范围是1 … 65535。
假设有三台机器,则DB1中order表的起始ID值为1,DB2中order表的起始值为2,DB3中order表的起始值为3,它们自增的步长都为3,则它们的ID生成范围如下图所示:
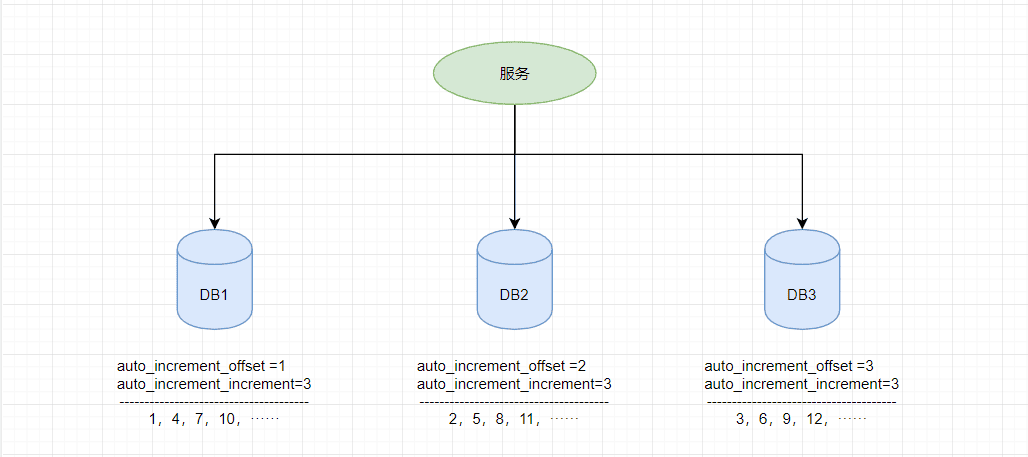
通过这种方式明显的优势就是依赖于数据库自身不需要其他资源,并且ID号单调自增,可以实现一些对ID有特殊要求的业务。
但是缺点也很明显,首先它强依赖DB,当DB异常时整个系统不可用。虽然配置主从复制可以尽可能的增加可用性,但是数据一致性在特殊情况下难以保证。主从切换时的不一致可能会导致重复发号。还有就是ID发号性能瓶颈限制在单台MySQL的读写性能。
- 标题: 分布式唯一ID-数据库生成
- 作者: Heer Liu
- 创建于: 2022-08-08 20:49:08
- 链接: https://blog.heer.love/posts/63cd793d/
- 版权声明 : 本文章采用 CC BY-NC-SA 4.0 进行许可。
